
E-mail messages contain numerous metadata fields that are utilized by computer forensic examiners as well as legal teams. One key MAPI property that is frequently extracted by computer forensics and e-Discovery software, but yet usually overlooked or underutilized, is e-mail conversation index (PR_CONVERSATION_INDEX).
The e-mail conversation index property indicates the relative position of a message within a conversation thread and is typically populated by the e-mail client for each outgoing message. Information extracted from the PR_CONVERSATION_INDEX property can help answer key questions such as:
- Is the message in question a new message, or was it created by replying to or forwarding another message?
- If the message is part of an e-mail thread, when was the thread started?
- When were other messages in the e-mail thread created?
MSDN Documentation
Microsoft has an article titled Tracking Conversations on how the e-mail conversation index (PR_CONVERSATION_INDEX) value is calculated. According to the article (quoted directly from their website):
- ScCreateConversationIndex implements the index as a header block that is 22 bytes in length, followed by zero or more child blocks each 5 bytes in length.
- The header block is composed of 22 bytes, divided into three parts:
- One reserved byte. Its value is 1.
- Five bytes for the current system time converted to the FILETIME structure format.
- Sixteen bytes holding a GUID, or globally unique identifier.
- Each child block is composed of 5 bytes, divided as follows:
- One bit containing a code representing the difference between the current time and the time stored in the header block. This bit will be 0 if the difference is less than .02 second and greater than two years and 1 if the difference is less than one second and greater than 56 years.
- Thirty one bits containing the difference between the current time and the time in the header block expressed in FILETIME units.This part of the child block is produced using one of two strategies, depending on the value of the first bit. If this bit is zero, ScCreateConversationIndex discards the high 15 bits and the low 18 bits. If this bit is one, the function discards the high 10 bits and the low 23 bits.
- Four bits containing a random number generated by calling the Win32 function GetTickCount.
- Four bits containing a sequence count that is taken from part of the random number.
However, our experience differs from Microsoft’s documentation in three areas:
- The first byte of the e-mail conversation index is not merely a fixed-value reserved byte, but is also a part of the FILETIME structure that follows it.
- The 6-byte FILETIME value (including the reserved byte) is actually the 6 most significant bytes of the 8-byte FILETIME structure, and needs to be padded with 2 bytes of zeroes.
- The time difference values found in the child blocks do not indicate the difference in time from the header date, but from the date of the previous child block.
Further research on the discrepancies above revealed that Joachim Metz of Hoffmann Investigations noted the same issues as #1 and #3 above in his article titled “E-mail and appointment falsification analysis”.
Example Calculation
Let’s take a look at an example and try to make sense of the e-mail conversation index (PR_CONVERSATION_INDEX) value.
PR_CONVERSATION_INDEX
01CDE90ABFE0D78F0E4280824120B2F1D0E3C07ED0070000CCBA300000114460 (32-bytes)
Based on the Microsoft documentation, the e-mail conversation index is divided as follows:
| FILETIME Value | GUID | Child Block 1 | Child Block 2 |
| 01CDE90ABFE0 | D78F0E4280824120B2F1D0E3C07ED007 | 0000CCBA30 | 0000114460 |
Figure 1 – Breakdown of Example PR_CONVERSATION_INDEX
After the zero padding, the header timestamp value becomes 01CDE90ABFE00000. This value is expressed in FILETIME units, and therefore represents the number of 100-nanosecond units since the start of January 1, 1601. When 0x01CDE90ABFE00000 is converted to decimal, we find that the timestamp represents 130,016,196,641,685,504 100-nanosecond units since the start of January 1, 1601, which corresponds to January 2, 2013 17:01:04 (UTC). This matches the sent date (PR_CLIENT_SUBMIT_TIME) of the original e-mail in the e-mail thread.
The following 16-bytes represent the following GUID: d78f0e42-8082-4120-b2f1-d0e3c07ed007.
The following 5 bytes, 0000CCBA30, contain the data for the first child block. When we convert 0x0000CCBA30 to binary, we find the following 40-bit value:
0000000000000000110011001011101000110000.
According to Microsoft’s documentation, the bits are divided as follows:
| Code Bit (1 bit) | Time Difference (31 bits) | Random Number (4 bits) | Sequence Count (4 bits) |
| 0 | 0000000000000001100110010111010 | 0011 | 0000 |
Figure 2 – Breakdown of Example Child Block
Since the first bit is 0, we assume that the high 15 bits and the low 18 bits were discarded when the time difference value was being calculated. Once the discarded digits are added, the FILETIME value becomes the following 64-bit binary string:
0000000000000000000000000000001100110010111010000000000000000000
When converted to decimal, this value represents 13,738,967,040 100-nanosecond units, which is approximately a 22 minute and 53.897 second time span. When added to the header date, we find that the date of Child Block 1 was January 2, 2013 17:23:58 (UTC). After converting the random number and sequence count bits to decimal, we find that the values are 3 and 0 respectively.
Same calculations on Child Block 2 indicate that the time difference for this message is 1 minute and 55.868 seconds and the random number and sequence count values are 6 and 0 respectively.
The final results are as follows:
Download Conversation Index Parser
We realize that performing these calculations on multiple messages can be quite tedious. We have created a free utility called Conversation Index Parser which extracts the information from the PR_CONVERSATION_INDEX value. If you would like to download a copy, please leave us your e-mail address below and we will get back to you with the download link.
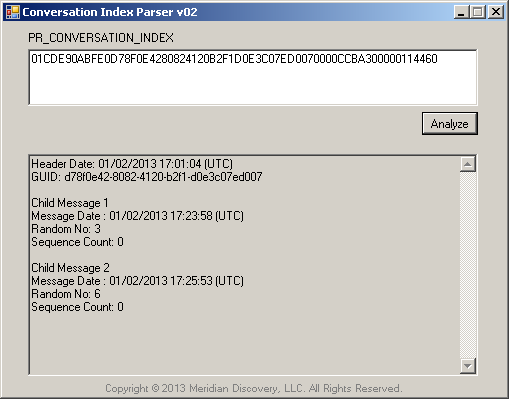
Figure 3 – Conversation Index Parser v02 Screenshot
Observations
We have made the following observations while analyzing the conversation index (PR_CONVERSATION_INDEX) properties of numerous e-mails:
- When creating a new message, Outlook populates the header date in the e-mail conversation index (PR_CONVERSATION_INDEX) with the local timestamp when the message is sent (i.e. PR_CLIENT_SUBMIT_TIME).
- When replying to or forwarding a message, Outlook updates the e-mail conversation index (PR_CONVERSATION_INDEX) property and sets the time difference in the child block based on when the new message is created, not when it is sent. For example, let’s assume that person A receives an e-mail from person B and hits the reply button in Outlook at 3:00:00 PM. She then takes 10 minutes to compose her answer and send the e-mail. The time difference value contained in PR_CONVERSATION_INDEX would reflect the difference in time between 3:00:00 PM (when person A created the new message) and the timestamp of the previous message.
- Outlook calculates the time difference values based on the user’s local time. When multiple users with slightly different computer times participate in an e-mail conversation, the calculated time difference values in PR_CONVERSATION_INDEX would reflect this discrepancy. For example, let’s assume that person C creates and sends a message to person D at precisely 4:00:00 PM. Person D’s computer time is 5 minutes ahead, and shows 4:05:00 PM at this moment. Person D creates a response message at 4:20:00 PM according to his computer (4:15:00 PM according to Person C’s computer). This would cause Person D’s Outlook to calculate a 20 minute time difference value when, in reality, only 15 minutes passed between the two events.
- The time difference values found in the child blocks are unsigned. While one would normally assume that the time differences in an e-mail conversation would be positive (i.e. a response would be created after the original message), it is possible that the original time difference might have been negative due to a large difference in local computer times or due to tampering. For example, let’s assume that person E sends person F a message at 5:00:00 PM, and person F’s computer time was set to 4:50:00 PM at this moment (10 minutes behind that of person E). If person F replies to this message at 4:54:00 PM according to his computer (5:04:00 PM according to person E’s computer), person F’s Outlook would record a time difference value of 6 minutes while the difference (according to the local computer times) was -6 minutes.
Conclusions
Combined with additional evidence from the e-mail server or internal e-mail metadata, the information contained in the e-mail conversation index (PR_CONVERSATION_INDEX) MAPI property can be very helpful in the forensic analysis of e-mails. We believe that forensic examiners would benefit from understanding how and when this property is populated and which factors (such as the accuracy of the local computer time) affect the reliability of this information.