
Portable Document Format (PDF) forensic analysis is a type of request we encounter often in our computer forensics practice. The requests usually entail PDF forgery analysis or intellectual property related investigations. In virtually all cases, I have found that the PDF metadata contained in metadata streams and the document information dictionary have been instrumental. I will provide a brief overview of these metadata sources and then provide an example of how they can be useful during PDF forensic analysis.
PDF is an electronic file format created by Adobe Systems in the early 1990s. It is used primarily to reliably exchange documents independent of platform—hardware, software or operating system. PDF is also an ISO Standard (ISO 32000-1). Due to its platform independent nature, numerous personal and business documents such as reports, agreements and operational documents are created and exchanged in PDF format. Consequently, we encounter them very often during e-Discovery processing, productions and PDF forensic analysis—especially during fraudulent document analysis.
PDF Metadata
In the computer forensics context, PDF files can be a treasure trove of metadata. Metadata can be stored in a PDF document in a document information dictionary and/or in one or more metadata streams. A metadata stream, whose contents are represented in Extensible Markup Language (XML), may contain metadata for an entire document, and for components within a document.
Extensible Metadata Platform (XMP)
XMP is a document labeling technology originally created by Adobe Systems. XMP allows metadata to be embedded into electronic documents, and enables software and systems to capture, share and utilize document metadata as well as maintain document context and relationships throughout the document lifecycle. The format of the XML representing the metadata in a metadata stream is defined as part of the XMP framework.
XMP Metadata Example
The listing below contains an XMP Packet—an instance of the XMP data model—which was extracted from the metadata stream of a sample PDF file.
<?xpacket begin="" id="W5M0MpCehiHzreSzNTczkc9d"?>
<x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 5.4-c005 78.147326, 2012/08/23-13:03:03 ">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about=""
xmlns:xmpMM="http://ns.adobe.com/xap/1.0/mm/"
xmlns:stRef="http://ns.adobe.com/xap/1.0/sType/ResourceRef#"
xmlns:stMfs="http://ns.adobe.com/xap/1.0/sType/ManifestItem#"
xmlns:xmp="http://ns.adobe.com/xap/1.0/"
xmlns:xmpGImg="http://ns.adobe.com/xap/1.0/g/img/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:pdf="http://ns.adobe.com/pdf/1.3/">
<xmpMM:InstanceID>uuid:3e8ceeea-4d84-4aaf-a6d7-6670737e98c3</xmpMM:InstanceID>
<xmpMM:DocumentID>adobe:docid:indd:7e4f4ef6-3b88-11dc-b902-bffb0f547c67</xmpMM:DocumentID>
<xmpMM:RenditionClass>proof:pdf</xmpMM:RenditionClass>
<xmpMM:DerivedFrom rdf:parseType="Resource">
<stRef:instanceID>0e5588c7-32bc-11dc-a4f2-d246f1100dc8</stRef:instanceID>
<stRef:documentID>adobe:docid:indd:043e6c68-1cb9-11dc-8b22-d0cf6f8f7ed9</stRef:documentID>
</xmpMM:DerivedFrom>
<xmp:CreateDate>2007-07-27T13:08:49+01:00</xmp:CreateDate>
<xmp:ModifyDate>2011-09-14T13:07:28-07:00</xmp:ModifyDate>
<xmp:MetadataDate>2011-09-14T13:07:28-07:00</xmp:MetadataDate>
<xmp:CreatorTool>Adobe InDesign CS3 (5.0)</xmp:CreatorTool>
<dc:format>application/pdf</dc:format>
<pdf:Producer>Adobe PDF Library 8.0</pdf:Producer>
<pdf:Trapped>False</pdf:Trapped>
</rdf:Description>
</rdf:RDF>
</x:xmpmeta>
<?xpacket end="w"?>
Listing 1 – Example XMP Metadata Packet (Abbreviated)
Some of the XMP metadata properties in the XMP packet that can be interesting during PDF forensic analysis are as follows:
xmpMM:DocumentID: This property is populated with a Globally Unique Identifier (GUID) which identifies all versions of a resource.
xmpMM:InstanceID: This property is also a GUID, and is updated each time a file is saved. It refers to each specific version of a resource.
xmpMM:DerivedFrom: This section is a reference to the resource from which the current document was derived. Within this section, we see the stRef:documentID and stRef:instanceID properties which represent the xmpMM:DocumentID and xmpMM:InstanceID values of the referenced resource.
xmpMM:RenditionClass: This property indicates the form or intended usage of a resource. Some of the defined values for rendition tokens are “default”, “draft”, “low-res”,
“proof”, “screen” and “thumbnail”. In this example, the “proof” token was used, which indicates that the intended usage of this resource was a review proof.
xmp:CreateDate: This is the date and time the resource was created. If the resource was freshly created—in the absence of operations that may change file system metadata such as copying—this value is expected to be close to the file system creation timestamp. Part of the difference stems from the time it takes to complete writing the file. In this example, the creation date is 2007-07-27T13:08:49+01:00 [07/27/2007 1:08:49 PM (UTC+01:00)]. Please note that the CreateDate property includes the time zone offset, which can be valuable during PDF forensic analysis.
xmp:ModifyDate: This property represents the date and time the resource was last modified. This value is typically set before the file is written to the file system. Therefore, the ModifyDate property is expected to be earlier than the file system modification timestamp for the resource. In this case, the modification date is 2011-09-14T13:07:28-07:00 [09/14/2011 1:07:28 PM (UTC-07:00)].
xmp:MetadataDate: This property represents the date and time when any metadata for this resource was last modified. The value is expected to be the same as, or more recent than the xmp:ModifyDate property value.
xmp:CreatorTool: This property is populated with the name of the first known tool that was used to create this resource. In this case, the name of the tool is Adobe InDesign CS3 (5.0).
pdf:Producer: This property is populated with the name of the tool that was used to create the PDF document. In this case, the PDF document was created using Adobe PDF Library 8.0.
pdf:Trapped: This property is a Boolean value that indicates whether the document has been trapped. Trapping is a pre-press process which introduces color areas into color separations in order to obscure potential register errors.
XMP Metadata Notes for PDF Forensic Analysis
The following notes should be kept in mind when using XMP metadata during PDF forensic analysis:
- A metadata stream can be associated with a document, or a component of a document. Consequently, a document may contain multiple metadata streams—multiple XMP packets. For instance, the sample document mentioned in this post contained 10 metadata streams. Listing 1 above shows only one of them—the metadata stream that was attached to the document via the metadata entry in the PDF document catalogue (i.e., the metadata stream that was associated with the document).
- A PDF file may have been saved by a writer that is not aware of metadata streams. For example, if the document modification timestamp recorded in the document information dictionary is later than the metadata modification timestamp of the metadata stream attached to the document, it is likely that the document was modified by such a writer.
- A metadata stream may contain much more comprehensive information than the example above. For example, the XMP Media Management namespace, which contains information typically used by digital asset management (DAM) systems, can have properties such as xmpMM:History and xmpMM:Ingredients in addition to the properties—such as xmpMM:InstanceID and xmpMM:DocumentID—we have seen in Listing 1. The xmpMM:History is an array of ResourceEvents that describe the steps taken to make the changes from the previous version of a resource to its current version. You can imagine how this can be a gold mine for PDF forensic analysis.
PDF Document Information Dictionary
The document information dictionary is another structure that can be useful during PDF forensic analysis. Document information dictionary is an optional info entry in the trailer of a PDF file that also contains metadata for the PDF document. According to the PDF 1.7 specification, the document information dictionary contains the following entries—applications may store custom metadata in the document information dictionary in addition to the following entries. All of the entries below are optional, except for ModDate if PieceInfo is present in the document catalogue.
| Entry Key | Data Type | Description |
|---|---|---|
| Title | text string | Title of the document. |
| Author | text string | Author of the document. |
| Subject | text string | Subject of the document. |
| Keywords | text string | Keywords associated with the document. |
| Creator | text string | The name of the tool that created the original document if this document was converted to PDF from another format. |
| Producer | text string | The name of the tool that converted the document to PDF if it was converted from another format. |
| CreationDate | date | The date time the document was created. |
| ModDate | date | The date time the document was last modified. |
| Trapped | name | Whether or not the document was modified to include trapping information. Can be True, False or Unknown (default). |
Table 1 – Entries in the document information dictionary
Here is how the document information dictionary looked for the sample file. Please note that the values below match those of their semantically equivalent counterparts in the metadata stream for the document.
294 0 obj
<< /CreationDate(D:20070727130849+01'00')
/Creator(Adobe InDesign CS3 \(5.0\))
/ModDate(D:20110914130728-07'00')
/Producer(Adobe PDF Library 8.0)
/Trapped/False
>>
endobj
Listing 2 – Example Document Information Dictionary
PDF Forensic Analysis Example
Let’s take a look at an example scenario where we can put some of this information to use. Below is a screenshot of the Document Properties dialog of Adobe Acrobat for a document named “CompanyFinancials.pdf”.
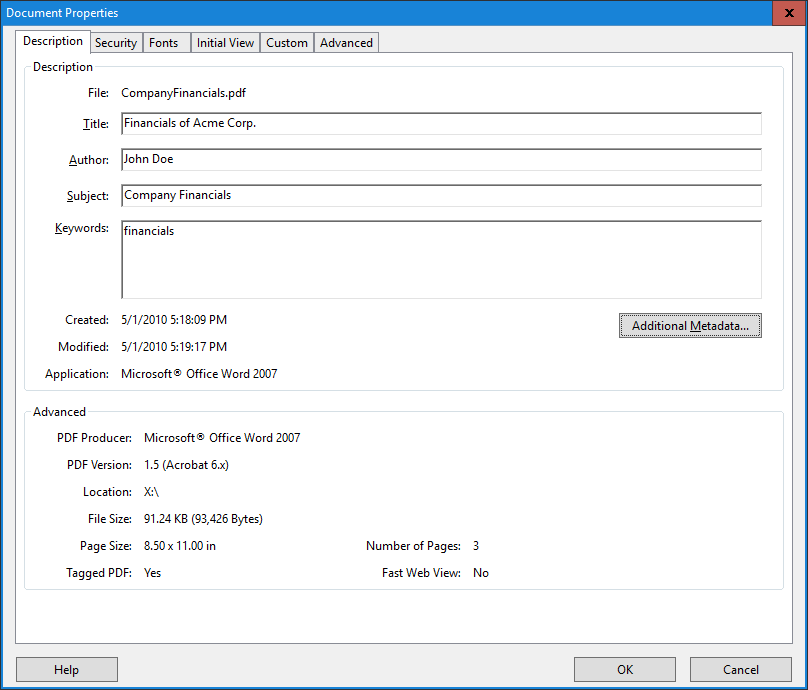
Figure 1 – PDF Document Properties
Before we dig deeper, it is important to note that the timestamps on this screenshot (i.e., the created and modified date values) are not time zone adjusted. In other words, they display the time value without taking into consideration whether or not the viewer’s computer is set to the same time zone.
Let’s press the “Additional Metadata…” button and see what’s available there:
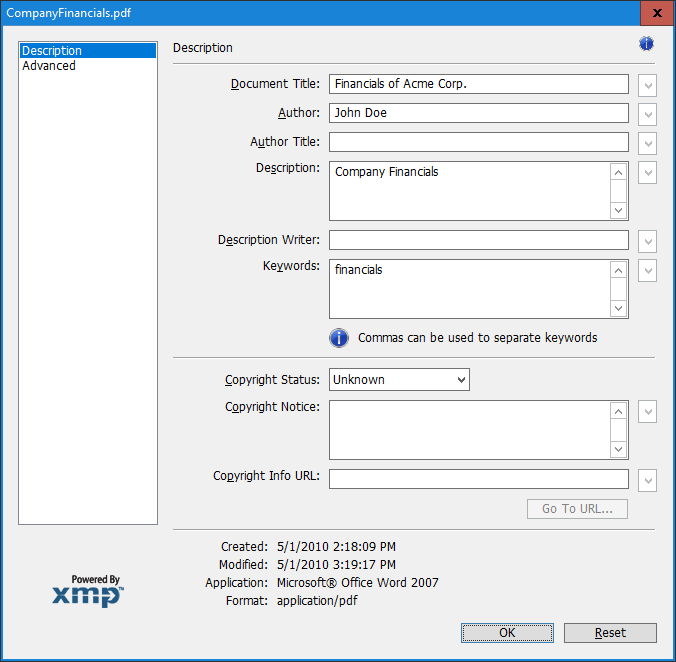
Figure 2 – Additional PDF Metadata
In Figure 2, we see the same timestamp values, but this time adjusted to reflect time zone differences. For instance, the creation timestamp was adjusted from 5/1/2010 5:18:09 PM to 5/1/2010 2:18:09 PM. This is because the time zone where this document was created is ahead of my time zone by three hours (Eastern Time as opposed to Pacific Time). However, the modification date is adjusted by two hours only from 5/1/2010 5:19:17 PM to 5/1/2010 3:19:17 PM. Let’s take a look at the underlying metadata stream to see the full timestamps with offsets.
<?xpacket begin="" id="W5M0MpCehiHzreSzNTczkc9d"?>
<x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 5.4-c005 78.147326, 2012/08/23-13:03:03 ">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about=""
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:xmp="http://ns.adobe.com/xap/1.0/"
xmlns:pdf="http://ns.adobe.com/pdf/1.3/"
xmlns:xmpMM="http://ns.adobe.com/xap/1.0/mm/">
<dc:format>application/pdf</dc:format>
<dc:creator>
<rdf:Seq>
<rdf:li>John Doe</rdf:li>
</rdf:Seq>
</dc:creator>
<dc:description>
<rdf:Alt>
<rdf:li xml:lang="x-default">Company Financials</rdf:li>
</rdf:Alt>
</dc:description>
<dc:title>
<rdf:Alt>
<rdf:li xml:lang="x-default">Financials of Acme Corp.</rdf:li>
</rdf:Alt>
</dc:title>
<dc:subject>
<rdf:Bag>
<rdf:li>financials</rdf:li>
</rdf:Bag>
</dc:subject>
<xmp:CreateDate>2010-05-01T17:18:09-04:00</xmp:CreateDate>
<xmp:CreatorTool>Microsoft® Office Word 2007</xmp:CreatorTool>
<xmp:ModifyDate>2010-05-01T17:19:17-05:00</xmp:ModifyDate>
<xmp:MetadataDate>2010-05-01T17:19:17-05:00</xmp:MetadataDate>
<pdf:Keywords>financials</pdf:Keywords>
<pdf:Producer>Microsoft® Office Word 2007</pdf:Producer>
<xmpMM:DocumentID>uuid:5f0b49c0-cb7d-4212-a633-1dfc95de8b12</xmpMM:DocumentID>
<xmpMM:InstanceID>uuid:f7754963-6525-43e5-b005-7d9c862512a9</xmpMM:InstanceID>
</rdf:Description>
</rdf:RDF>
</x:xmpmeta>
<?xpacket end="w"?>
Listing 3 – Second Example XMP Metadata Packet (Abbreviated)
When we look at the XMP metadata, it becomes clear that the creation date is 05/01/2010 5:18:09 PM (UTC-04:00). UTC-04:00 is the correct time zone for Eastern Time in the United States in May since Daylight Savings would be in effect. In other words, this reflects Eastern Daylight Time (EDT).
When we look at the last modification date, we see that it is 05/01/2010 5:19:17 PM (UTC-05:00). Although the modification time appeared to be just 1 minute and 8 seconds after the creation time in the Document Properties dialog (see Figure 1), we now see that this is not the case. The modification timestamp is still in May, but the time zone offset (UTC-05:00) does not reflect the offset of EDT.
From a PDF forensic analysis standpoint, there might be a number of reasons for this discrepancy. A few examples:
- The PDF might have actually been edited by someone else in a time zone with (UTC-05:00) offset on the same date, 1 hour 1 minute and 8 seconds after it was created. For example, Central Daylight Time (CDT) would have (UTC-05:00) offset in May.
- The PDF might have been modified on a device that does not have Daylight Savings configured correctly.
- The PDF might have been modified by someone in Eastern Standard Time (e.g., in winter) having rolled back their system clock to reflect 05/01/2010 5:19:17 PM without taking Daylight Savings into consideration.
Needless to say, forensic analysis of this PDF would not stop here. Additional metadata from other metadata streams within the same document as well as other artifacts from the device(s) where the PDF was created and modified can be used to tell the whole story.
References:
- Adobe XMP Specification Part 1 and Part 2
- Document management — Portable document format — Part 1: PDF 1.7